| RIP stands for Routing Information Protocol. RIP is a dynamic, distance vector routing protocol and was developed for smaller IP based networks. As mentioned earlier, RIP calculates the best route based on hop count. There are currently two versions of RIP protocol.
|
1. Hop Count Limit: Destination that is more than 15 hops away is considered unreachable by RIPv1.
2. Classful Routing Only: RIP is a classful routing protocol. RIPv1 doesn't support classless routing. RIP v1 advertises all networks it knows as classful networks, so it is not possible to subnet a network using RIP v1.
3. Metric limitation: The best route in RIP is determined by counting the number of hops required to reach the destination. A lower hop count route is always preferred over a higher hop count route. One disadvantage of using hop count as metric is that if there is a route with one additional hop, but with significantly higher bandwidth, the route with smaller bandwidth is taken. This is illustrated in the figure below:
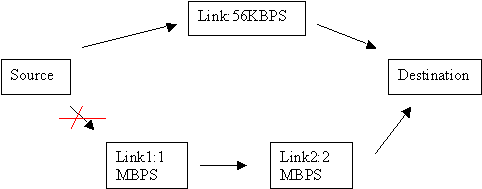
The RIP routed packets take the path through 56KBPS link since the destination can be reached in one hop. Though, the alternative provides a minimum bandwidth of 1MBPS (though using two links of 1MBPS, and 2MBPS each), it represents 2 hops and not preferred by the RIP protocol.
Features of RIP v2:
RIP v2 is a revised version of its predecessor RIP v1. The following are the important feature enhancements provided in RIPv2:1. RIPv2 packets carry the subnet mask in each route entry, making RIPv2 a classless routing protocol. It provides support for variable-length subnet masking (VLSM) and classless addressing (CIDR).
2. Next Hop Specification: In RIPv2, each RIP entry includes a space where an explicit IP address can be entered as the next hop router for datagrams intended for the network in that entry.
For example, this field can be used when the most efficient route to a network is through a router that is not running RIP. Since, that a router will not exchange RIP messages, explicit Next Hop field allows the router to be selected as the next hop router.
3. Authentication: RIPv1 does not support authentication. This loophole may be used maliciously by hackers, that may resulting in delivering the data packets to a fictitious destination as determined by the hacker. RIPv2 provides a basic authentication scheme, so that a router can accept RIP messages from a neighboring router only after ascertaining its authenticity.
4. Route Tag: Each RIPv2 entry includes a Route Tag field, where additional information about a route can be stored. It provides a method for distinguishing between internal routes (learned by RIP) and external routes (learned from other protocols).
Limitations of RIP v2:
One of the biggest limitations of RIPv1 still remains with RIPv2. It is hop count limitation, and metric. The hop count of 16 still remains as unreachable, and the metric still remains hop count. A smaller hop count limits the network diameter, that is the number of routers that can participate in the RIP network.Example Question:
While the packet travels from source to destination through an Internetwork, which of the following statements are true? (Choose 2 best answers).
A. The source and destination hardware (interface) addresses change
B. The source and destination hardware (interface) addresses remain constant.
C. The source and destination IP addresses change
D. The source and destination IP addresses remain constant.
Ans. A, D
Explanation: While a packet travels through an Internetwork, it usually involves multiple hops. It is important to know that the logical address (IP address) of the source (that created the packet) and destination (final intended destination) remain constant, whereas the hardware (interface) addresses change with each hop.
Comments
Post a Comment